监控分享
Author: fupeng.li
date: 2020-05-14
关键字:监控系统, statsd,telegraf, influxdb,grafana
概念简介
监控系统包括三部分:客户端(client)、服务器(server)和后端(backend)。客户端植入于应用代码中(可以是一个现成的包或者自己集成的代码),将相应的 metrics 上报给 statsd server。statsd server 聚合这些metrics 之后,定时发送给 backends。backends 则负责存储这些时间序列数据,并通过适当的图表工具展示。
statsd(server服务端)狭义来讲,其实就是一个监听UDP(默认)或者TCP的服务,根据简单的协议收集 statsd客户端发送来的数据,聚合之后,定时推送给后端,如 graphite 或者 influxdb等,再通过 grafana 等展示。
需求
了解了监控系统的基本概念,在系统选型前,有必要先梳理我们的需求,只有明确需求,才能有合适的选择:
- 业务指标类数据,需要表格展示,一般只关心最新状态
- 时间序列数据,按时间轴展开分析,如各种系统延时
- 开源,易扩展,方便二次开发
- 能够直观展示告警数据
涉及到的模块
我们希望监控系统能采用开放性的架构,各个部件可以根据业务需要、开源社区发展程度进行调整。一般来说监控系统都有如下功能模块,我们将分别讨论。
-
上报
-
收集
-
存储
-
展示
-
告警
-
分析
传统的 tick 架构
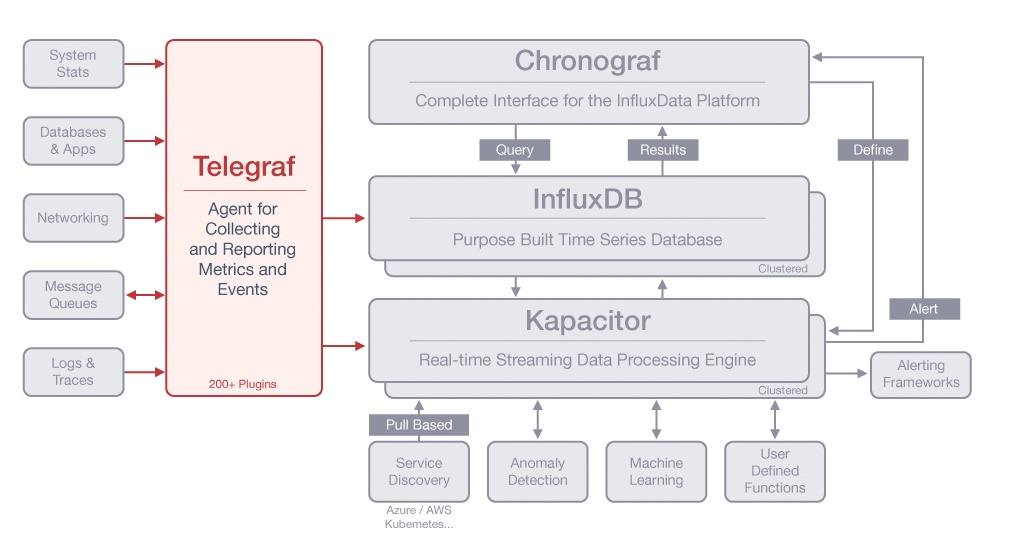
我们用的实际上是将 chronograf 和 kapacitor 集合成一个了的 grafana, 我们称之为 TIG
数据的上报 —> 客户端
收据的上报的功能由客户端来实现,由非常多的开源的方案来实现,GitHub上收集了目前比较流行的语言的客户端实现,地址在此
stats 的客户端植入与应用代码中,或者就是我们应用代码的一个模块或者一个集成好的第三方包,我们利用客户端,在我们需要的地方,记录想要监控的指标(API的请求次数,200的次数,4XX的次数等等)。记录的指标主要的分类有count,timing等,即数量指标与时间指标(数量指标比如,一分钟内有多少次请求数,时间指标比如一个请求的生命周期耗时多久)。
一般客户端通过UDP的通信方式,将数据发送到 telegraf 服务的8125端口。
我们以golang的一个简单包https://github.com/cactus/go-statsd-client为例,简单介绍下监控指标的记录与上报,完整的文档戳这里。
import (
"log"
"github.com/cactus/go-statsd-client/statsd"
)
func main() {
// first create a client
// The basic client sends one stat per packet (for compatibility).
client, err := statsd.NewClient("127.0.0.1:8125", "test-client")
// A buffered client, which sends multiple stats in one packet, is
// recommended when your server supports it (better performance).
// client, err := statsd.NewBufferedClient("127.0.0.1:8125", "test-client", 300*time.Millisecond, 0)
// handle any errors
if err != nil {
log.Fatal(err)
}
// make sure to clean up
defer client.Close()
// Send a stat
client.Inc("stat1", 42, 1.0)
client.Count("stat2", 3)
client.Timing("stat3", 200)
}
从这个demo我们可以看到,客户端将指标发送到本机8125端口,具体的方法见详细文档。
数据的采集 —> 服务端
采集这方面已经有很多成熟的项目,如python的Py-Statsd,点击这里获得地址;如golang实现的gostatsd,都大同小异。其中telegraf 是 influxdata 公司的产品,它支持 influxdb 特有的 key 与 field 格式。如果使用 influxdb 的话,最好就用 telegraf 。当然对于业务系统数据,可能会考虑直接往 influxdb 发送数据;telegraf 只负责采集系统级别的监控数据,当然telegraf自己全部负责了也是OK的。
存储 —> 后端时序数据库 (核心,优先选择)
这个监控系统最核心的是存储模块,数据的存储基本决定了展示和分析的形态。mysql不是很适合大量的时间序列类数据的频繁写入存储,所以为了监控系统的方方面面,存储必须足够高效 。要求存储系统 简单易用 ,且 表达能力 足够满足基本查询、分析需要。
influxdb 采用简洁而高效的 TSM 文件结构,查询语言基本与 sql 一致。
另外一个选择是 graphite,但由于其存储格式是固定时间间隔都要占坑,对于稀疏数据非常浪费空间;且每个 metric 都对应于一个独立的文件,同时写入多个 metric 会产生很多零碎的文件 IO 操作,已经有不少关于这方面性能问题的吐槽。所以我们选择了 influxdb 作为存储系统。
展示 —> 后端界面服务
传统的 TICK 架构里的 Chronograf 作为展示模块,功能过于简单,无法满足需求。而另外一个成熟的 Grafana 项目,从 Graphite 时代就发展起来,拥有丰富的展示功能,强大而方便的可配置界面和插件系统,且可以批量创建管理展示配置,最关键的是与 influxdb 适配也非常成熟稳定(influxdata 的支持)。
告警 —> 后端警报服务 alert manager
监控系统的成败就在于能否恰当地告警了。Grafana 自带报警功能,报警内容能在图标上直观地展示,这样出报警时可以方便查看报警情况。不过 Grafana 的报警功能比较简单,只支持简单的阈值检查,所以这里还需要我们实现一些辅助分析,把复杂的报警需求转化成可以做简单阈值检查的指标数据。
TICK 架构包含了 Kapacitor 这一告警子系统,但它并不能直接支持展示,虽然足够强大但表达能力毕竟还是受限, 但是可以作为一个备选项。
分析
分析模块可以自己定制,因为不同的项目需要分析的指标不同,侧重的维度也不同,建议直接手动代码实现,对 influxdb 数据库内的数据进行操作。
通过上面的分析,我们基本确定好了选型的方案。
- 客户端:
go-statsd-client - 服务端:直接采用
telegraf即可 - 后端:
influxdb+grafana
Telegraf 配置文件分析
Telegraf有四种类型的插件:
- 输入插件(Inputs):收集各种时间序列性指标,包含各种系统信息和应用信息的插件。
- 处理插件(Process):当收集到的指标数据流要进行一些简单处理时,比如给所有指标添加、删除、修改一个Tag。只是针对当前的指标数据进行。
- 聚合插件(Aggregate):聚合插件有别于处理插件,就在于它要处理的对象是某段时间流经该插件的所有数据(所以,每个聚合插件都有一个
period设置,只会处理now()-period时间段内的数据),比如取最大值、最小值、平均值等操作。 - 输出插件(Outputs):收集到的数据,经过处理和聚合后,输出到数据存储系统,可以是各种地方,如:文件、InfluxDB、各种消息队列服务等等。
文档: